- 用户
- 分类
- ChatGPT
- 文章
- 点赞
- 评论
- 聊天
- 通知
- 问题
- 购买token
- 数据模型
文章分页查询
GET
/article/page
使用MyBatis-Plus的
.page函数。请求参数
Query 参数
请求示例代码
Shell
JavaScript
Java
Swift
Go
PHP
Python
HTTP
C
C#
Objective-C
Ruby
OCaml
Dart
R
请求示例请求示例
Shell
JavaScript
Java
Swift
curl --location '/article/page?page=1&pageSize=10&categoryId='返回响应
🟢200成功
application/json
Bodyapplication/json
示例
{
"code": 200,
"msg": "success",
"data": {
"records": [
{
"articleId": "1703382093308137474",
"articleTitle": "【Boring Weekend】",
"articleContent": "❤️周末要过完了,但我真的很想吃海底捞!!\n\n",
"categoryId": "1688874327190704130",
"articleAbstract": "喵喵~有人找我玩嘛!",
"articlePic": "https://blog-picture-upload-bucket.oss-cn-beijing.aliyuncs.com/article_picture/6c5a0b46-7434-4b08-b47d-77da8c4d646a.png",
"likeCounts": 0,
"commentCounts": 0,
"userId": "1703381665786925057",
"createTime": "2023-09-17 20:15:13",
"updateTime": "2023-09-17 20:15:13",
"userName": "桃桃",
"userAvatar": "https://cube.elemecdn.com/0/88/03b0d39583f48206768a7534e55bcpng.png",
"isLike": null
},
{
"articleId": "1703376641350471682",
"articleTitle": "【项目部署】Maven打包、Vite打包、Nginx部署",
"articleContent": "- IDEA中 Java maven install打个jar包,丢到 `/root/code/chatviewer`文件夹下,执行\n `nohup java -jar blog-0.0.1-SNAPSHOT.jar > ./log/start.log 2>&1` & 命令启动\n- WebStorm中 `npm run build-only`,项目将生成在dist文件夹下\n 将文件夹中内容搬到 `/home/nginx/html`文件夹\n- 修改nginx的conf配置: `vim /home/nginx/conf/nginx.conf`\n- 查看nginx错误日志:`/home/nginx/log/error.log`,删除当前运行的nginx镜像 `docker rm -f nginx`\n\n- 启动新的nginx镜像:\n\n```bash\ndocker run -p 1022:80 \n--name nginx \n-v /home/nginx/conf/nginx.conf:/etc/nginx/nginx.conf \n-v /home/nginx/conf/conf.d:/etc/nginx/conf.d \n-v /home/nginx/log:/var/log/nginx \n-v /home/nginx/html:/usr/share/nginx/html -d nginx:latest\n```\n\n- 访问 http://<IP>:1022/ 即可\n",
"categoryId": "1688874327190704130",
"articleAbstract": "mark一下部署的流程。",
"articlePic": "https://blog-picture-upload-bucket.oss-cn-beijing.aliyuncs.com/article_picture/ava.jpeg",
"likeCounts": 2,
"commentCounts": 1,
"userId": "1703365214623535105",
"createTime": "2023-09-17 19:53:33",
"updateTime": "2023-09-17 19:53:33",
"userName": "木槿",
"userAvatar": "https://blog-picture-upload-bucket.oss-cn-beijing.aliyuncs.com/article_picture/19d51b93-e3a4-40b3-8e08-3d99d2a2ace7.jpg",
"isLike": null
},
{
"articleId": "1703374330079252482",
"articleTitle": "【操作系统】进程和线程",
"articleContent": "# 1 进程的概念与组成\n\n**程序**:静态的,存放在磁盘里的可执行文件,一系列的指令集合。\n\n**进程(Process)**:动态的,程序的一次执行过程。同一个程序的多次执行会产生不同的进程,OS会在进程创建时为其分配一个唯一的、不重复的进程ID (PID)。\n\n\n\n**进程控制块(PCB)**:操作系统需要对各个并发的进程进行管理,但凡管理时需要的信息,都会被放在PCB中。\n\n\n\n**程序的运行过程**:编译链接产生可执行文件,运行前创建对应的进程,即创建相应的PCB,把程序指令装入内存的程序段,运行过程中产生的各种数据装入数据段。\n\n# 2 进程的状态与转换\n\n\n\n> 注:在虚拟内存管理的操作系统中,通常会把阻塞状态的进程的物理内存空间换出到硬盘,等需要再次运行的时候,再从硬盘换入到物理内存,以避免浪费物理内存。进程没有占用实际的物理内存空间的情况,这个状态就是**挂起状态**。\n\n**PCB的组织形式**:(1)通常使用**链表**,把具有相同状态的进程链在一起,组成各种队列。(2)也有使用**索引**方式,将同一状态的进程组织在一个索引表中,索引表项指向相应的PCB,不同状态对应不同的索引表。\n\n\n\n# 3 进程的控制\n\n实现进程的**创建、终止、阻塞、唤醒**,这些过程也就是进程的控制。理解即可,不需要死记硬背过程。\n\n**原语**:一种特殊的程序,执行具有原子性,即这段程序的运行必须一气呵成、不可中断。\n\n### 1 进程创建(创建原语)\n\n\n\n### 2 进程终止(撤销原语)\n\n进程可以有3种终止方式:正常结束、异常结束以及外界干预(`kill` 掉)。\n\n```mermaid\ngraph LR;\n\t\tA(查找终止进程的PCB)-->B(正在运行?<br>剥夺CPU<br>CPU分给其他进程)\n\t\tB-->C(有子进程?<br>子进程交给1号进程接管)\n\t\tC-->D(资源归还OS)\n\t\tD-->E(将PCB从所在队列删除)\n```\n\n### 3 进程阻塞\n\n终止和阻塞的上一个状态只能是**运行态**。\n\n```mermaid\ngraph LR;\n\t\tA(找到被阻塞进程对应PCB)-->B(正在运行?<br>保护现场)\n\t\tB-->C(PCB插入阻塞队列)\n```\n\n### 4 唤醒进程\n\n因为何事阻塞,就应该由何事唤醒。\n\n进程由「运行」转变为「阻塞」状态必须等待某一事件的完成,处于阻塞状态的进程是绝对不可能叫醒自己的。\n\n```mermaid\ngraph LR;\n\t\tA(阻塞队列中<BR>找到相应进程的PCB)-->B(将其从阻塞队列中移出<BR>置其状态为就绪状态)\n\t\tB-->C(PCB插入到就绪队列中<BR>等待调度程序调度)\n```\n\n### 5 进程的切换\n\n**CPU 上下文切换**:先把前一个**任务**的 CPU 上下文(CPU 寄存器和程序计数器)保存起来,系统内核会存储保持下来的上下文信息,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。\n\n> 上面说到所谓的「任务」,主要包含进程、线程和中断。所以,可以根据任务的不同,把 CPU 上下文切换分成:**进程上下文切换、线程上下文切换和中断上下文切换**。\n\n**进程的上下文切换**:当时间片耗尽、当前进程主动阻塞、优先级更高进程到达、当前进程终止时,会发生进程上下文的切换。进程上下文不仅包含了虚拟内存、栈、全局变量等**用户空间**的资源,还包括了内核堆栈、寄存器等**内核空间**的资源。\n\n\n\n# 4 进程的通信\n\n每个进程的用户地址空间都是独立的,一般而言是不能互相访问的,但内核空间是每个进程都共享的,所以进程之间要通信必须通过内核。\n\n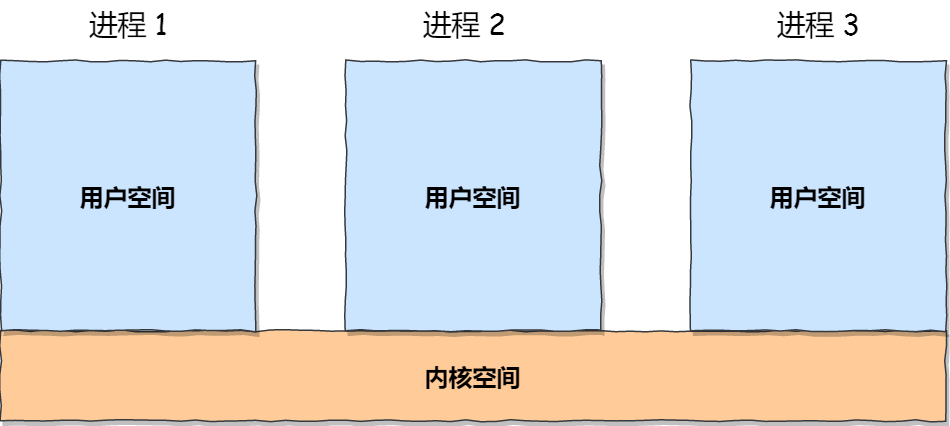\n\n## 1 管道\n\n\n\n比如在linux系统中可以通过以下方式创建一个管道:`ps auxf`的输出将作为`grep mysql`的输入。也可以通过`mkfifo`创建一个命名管道。管道只能传输字节流。\n\n```bash\n$ ps auxf | grep mysql\n\n$ mkfifo myPipe\n$ echo \"hello\" > myPipe\n$ cat < myPipe\n```\n\n## 2 消息队列\n\n管道的通信方式效率比较低,不适合进程之间频繁地交换数据。\n\n**消息队列是保存在内核中的消息链表**,在发送数据时,会分成一个一个独立的数据单元,也就是消息体(数据块),消息体是用户自定义的数据类型,消息的发送方和接收方要约定好消息体的数据类型,所以每个消息体都是固定大小的存储块,不像管道是无格式的字节流数据。\n\n\n\n- 不适合比较大数据的传输\n- 消息队列通信过程中,存在用户态和内核态的拷贝开销\n\n## 3 共享内存\n\n共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中。但需要采取保护机制,使得共享的资源,在任一时刻只能被一个进程访问。\n\n\n\n信号量提供了这一保护机制,信号量其实是一个整型的计数器,主要用于实现进程间的互斥与同步,PV操作需要同时出现。\n\n- 一个是 **P 操作**,这个操作会把信号量减去 1,**相减后**如果信号量 < 0,则表明资源已被占用,进程需阻塞等待;相减后如果信号量 >= 0,则表明还有资源可使用,进程可正常继续执行。\n- 另一个是 **V 操作**,这个操作会把信号量加上 1,**相加后**如果信号量 <= 0,则表明当前有阻塞中的进程,于是会将该进程唤醒运行;相加后如果信号量 > 0,则表明当前没有阻塞中的进程。\n\n\n\n**同步信号量**:在多进程里,每个进程并不一定是顺序执行的,它们基本是以各自独立的、不可预知的速度向前推进。比如进程 A 负责生产数据,进程 B 是负责读取数据,这两个进程是相互合作、相互依赖,进程 A 必须先生产了数据,进程 B 才能读取到数据,所以执行是有前后顺序的。\n\n## 4 Socket\n\n跨网络进程通信,创建 socket 的系统调用(指定协议族与通信特性):\n\n```c\nint socket(int domain, int type, int protocal)\n```\n\n- domain:指定协议族,比如 AF_INET 用于 IPV4、AF_INET6 用于 IPV6、AF_LOCAL/AF_UNIX 用于本机;\n- type :指定通信特性,比如 SOCK_STREAM 表示的是字节流,对应 TCP;SOCK_DGRAM 表示的是数据报,对应 UDP;SOCK_RAW 表示的是原始套接字。\n- protocal :原本用来指定通信协议的,现在基本废弃。因为协议已经通过前面两个参数指定完成,protocol 目前一般写成 0 即可。\n\n\n\nTCP:监听的 socket 和真正用来传送数据的 socket,是「**两个**」 socket,一个叫作**监听 socket**,一个叫作**已完成连接 socket**。\n\n# 5 线程的概念\n\n\n\n有的进程可能会同时做很多事。\n\n- [x] Choose 1:在同一个进程中直接串行运行不同功能,显然不行\n- [x] Choose2:将不同功能拆分为不同进程,但这种方式维护进程的系统开销较大(如创建进程时,分配资源、建立 PCB;终止进程时,回收资源、撤销 PCB;进程切换时,保存当前进程的状态信息)\n- [ ] 线程:并发运行且共享相同的地址空间。\n\n## 1 什么是线程\n\n**线程是进程当中的一条执行流程,是程序执行流的最小单位**。一个进程中可以同时存在多个线程,各个线程之间可以并发执行,各个线程之间可以共享地址空间和文件等资源。\n\n同一个进程内多个线程之间可以共享代码段、数据段、打开的文件等资源,但每个线程各自都有一套独立的寄存器和栈,这样可以确保线程的控制流是相对独立的。\n\n<img src=\"https://cdn.xiaolincoding.com/gh/xiaolincoder/ImageHost/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/%E8%BF%9B%E7%A8%8B%E5%92%8C%E7%BA%BF%E7%A8%8B/16-%E5%A4%9A%E7%BA%BF%E7%A8%8B%E5%86%85%E5%AD%98%E7%BB%93%E6%9E%84.jpg\" alt=\"多线程\" style=\"zoom: 50%;\" />\n\n## 2 线程的实现方式\n\n- **用户级线程**:由应用程序通过线程库实现,所有的线程管理工作都由应用程序负责(包括线程切换),**无需操作系统干预**,在用户看来有多个线程,但操作系统并不能意识到线程的存在。缺点:当一个用户级线程被阻塞后,整个进程都会被阻塞,并发度不高,多个线程不可以在多核处理机上并行运行。\n\n\n\n- **内核级线程**:一个线程被阻塞后,别的线程还可以继续执行,并发能力强,多线程可以在多核处理机上并行执行。缺点:一个用户进程会占用多个内核级线程,线程切换由操作系统完成,需要切换到内核态,线程管理的成本高,开销大。\n\n\n\n- **多线程模型**:\n - 一对一模型:一个用户级线程映射到一个内核级线程,有点像上述的内核级线程\n - 多对一模型:多个用户级线程映射到一个内核级线程,像上述的应用级线程\n - 多对多模型:折中,克服了多对一模型并发度不高的缺点 和 一对一模型占用太多内核级线程,开销太大的缺点\n\n\n\n## 3进程与线程的比较\n\n### 1 进程\n\n操作系统进行资源分配的单位(比如打印机、内存空间等),是一个独立运行的程序实体。拥有包括PCB、代码段、数据段等资源,进程之间的资源是相互隔离的,进程间通信需要通过**操作系统提供的特定机制**进行(管道、消息队列、共享内存等),进程间的切换与调度涉及到代码段和程序段的切换,这个过程开销较大。\n\n### 2 线程\n\n操作系统调度执行的最小单位,是进程内的一个执行流。一个进程可以拥有多个线程,这些线程共享进程的代码段、数据段、打开的文件等资源,但每个线程各自都有一套**独立的寄存器和栈**,这样可以确保线程的控制流是相对独立的。\n\n由于线程共享相同的资源,**线程间通信相对简单**,可以直接通过**共享变量、锁**等方式进行。线程相较于进程,上下文切换和调度开销较小。但多个线程并发执行时,需要处理好同步和互斥问题,以避免数据不一致或竞争条件。\n\n# 6 线程的状态与转换\n\nTODO\n\n",
"categoryId": "1688873487067418626",
"articleAbstract": "线程是进程当中的一条执行流程,是程序执行流的最小单位。一个进程中可以同时存在多个线程,各个线程之间可以并发执行,各个线程之间可以共享地址空间和文件等资源。",
"articlePic": "https://blog-picture-upload-bucket.oss-cn-beijing.aliyuncs.com/article_picture/4555b395-0748-4edf-886f-903625442b1e.png",
"likeCounts": 1,
"commentCounts": 1,
"userId": "1703365214623535105",
"createTime": "2023-09-17 19:44:22",
"updateTime": "2023-09-17 19:44:22",
"userName": "木槿",
"userAvatar": "https://blog-picture-upload-bucket.oss-cn-beijing.aliyuncs.com/article_picture/19d51b93-e3a4-40b3-8e08-3d99d2a2ace7.jpg",
"isLike": null
}
],
"total": 3,
"size": 10,
"current": 1,
"orders": [],
"optimizeCountSql": true,
"hitCount": false,
"countId": null,
"maxLimit": null,
"searchCount": true,
"pages": 1
}
}修改于 2023-09-28 07:49:30